Agent Framework Comparison: LlamaIndex vs. LangGraph vs. ADK

About the team
For the last 6 months, a small team consisting of 2 of my team mates and me has been deeply entrenched into researching LLM’s, agentic frameworks, tools, MCP, and other related terms one has to master to navigate the AI space.
We feel that we have done enough of research to at least reflect back and share our experiences and findings with those who are just entering the space of large language models, AI agents and frameworks.
Just to give everyone a little bit of more context about the people behind this article, all three of us are engineers with varying backgrounds and levels of expertise.
Luka has a lot of experience with 3D graphics and C++, Sara comes from a background of Machine learning and Python code, while I (Robert) have a diverse multiplatform knowledge that is focused on C++ and other OOP languages.
The Idea – LlamaIndex vs. LangGraph/LangChain vs ADK
We decided to use not just one, but three agentic frameworks, in a kind of side-by-side test where we attempt to achieve the same outcome with each of them. We chose three quite popular frameworks; LlamaIndex, LangGraph/LangChain, and Google Agent Development Kit (ADK).
How did we test the frameworks?
One of the first decisions one will encounter when faced with the task of building an AI agent is; which framework do I choose?
There are certainly more than enough to choose from, but which one is right for what you are trying to do can be a bit of a daunting task to figure out. Therefore, we decided to make a small comparison of three rather popular agentic frameworks and talk a little bit about the experience of working with each of them and what our verdict is, in the end.
For this purpose, we proposed a small project;
Create an agent that can search for content on Reddit, and return it in a nice, human-readable format.
The agent is to first search the entirety of Reddit, finding several subreddits which are relevant to the subject matter at hand, and then, traverse each of those subreddits finding and returning
content matching a certain keyword.
You might, for instance, tell the agent to “find all content mentioning Claude on LLM-related subreddits”, and it will then do its best to do exactly that. Once it is done obtaining the requested content, it will then present it in markdown format, grouped by a particular subreddit and listing all the posts it found on that subreddit, along with some short snippets such as poster, score, and the actual content of the post.
The nature of our task required that we develop an LLM agent. An LLM becomes an agent by being given access to various external tools, APIs, and resources, enabling it to have agency and perform certain tasks, such as browsing the web, checking for reservations, booking a flight, checking the weather, etc.
To facilitate the development of such agents, tools such as agent frameworks exist whose primary purpose is to do exactly that – develop agents with various capabilities and levels of complexity. A multitude of such frameworks already exist, and they all have their own specific approach to agent development.
We chose LlamaIndex, LangGraph/LangChain, and Google Agent Development Kit (ADK) and tested them on the same task side by side.
Each of them, as we are about to find out, have their peculiarities, strengths and weaknesses, and we will attempt to give our opinion, backed by our experience, on how each of them fares in this task.
Frontend – Setting up a unified communications channel
In order to have some way of interacting with our LLM and have data displayed in a readable format, we opted to implement a basic Gradio server with a
simple HTML interface.
Gradio is great for quick prototyping and booting up a small web GUI. The user would have the ability to type his query into a textbox, and after some time receive a response from the LLM with the content he requested.
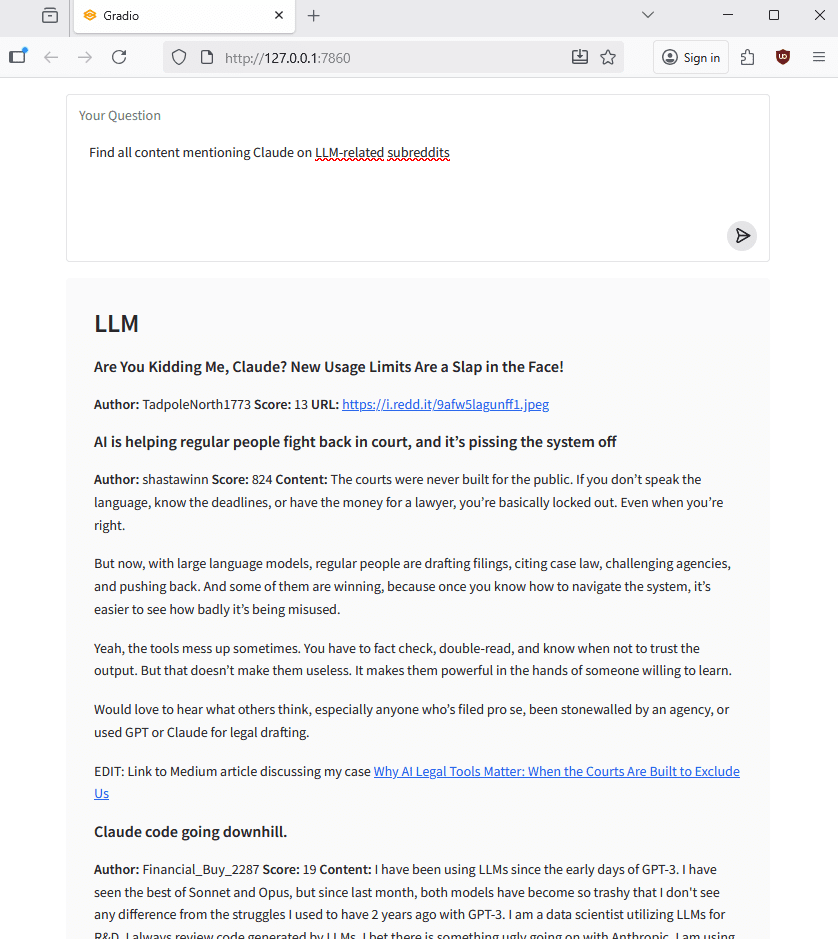
Thus, this GUI would serve as a unified communications channel between the user and the agent, regardless of which framework was used to build it and anything else happening in the background
To establish a unified communications channel for interacting with our LLM and displaying data in a clear, readable format, we opted to implement a basic Gradio server with a simple HTML interface. Gradio is well suited for rapid prototyping and quickly bootstrapping a lightweight web-based GUI.
We wanted for the user to have the ability to type his query into a textbox and receive a response from the LLM with the content he requested.
Backend/Agent layer
The models
These are the LLM brains of the whole operation. For this project, we decided to use GenAI models, specifically gemini-2.5-flash. Both the root and formatting agent use this same LLM, and they are always fixed regardless of the framework implementation.
The tools
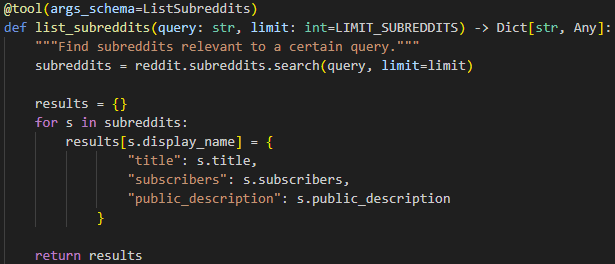
To have our LLM’s become agents we need to give them some means of interacting with the outside world, or specifically to access and search Reddit. To enable this, we had to create tools that the model will use.
We have tools that searching for relevant subreddits, and then another tool for traversing
the posts of a specific subreddit and finding ones that match the provided keywords. The tools must be properly described to the model, and this is quite important.
This description gives the LLM the context on what it can do with the tools, when it should use them, and most importantly what parameters the tool expects to work properly and what kind of output it is going to receive from the tool.
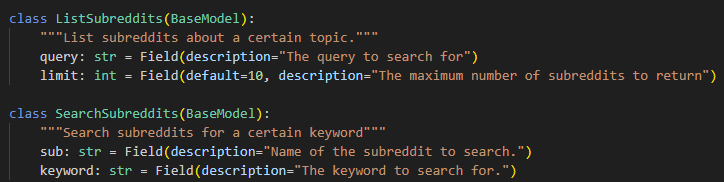
We decided to be quite meticulous about this and use Pydantic schemas to define the arguments that the tools can receive – this gives the model the maximum amount of information and helps it call the tools with proper arguments and in a structured manner.
The frameworks
This is the part where we branch off in three different directions. Although fundamentally all
three frameworks consist of similar components, in practice they are somewhat different.
LangGraph/LangChain
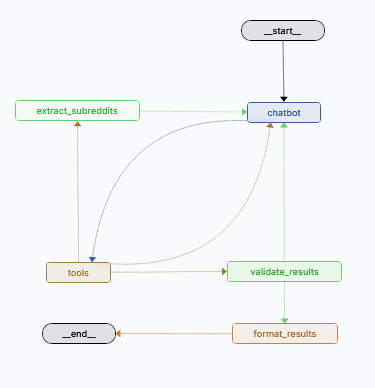
LangGraph operates by having a graph that consists of nodes. Each node can be considered
as a point of execution where some action can be performed (calling some Python code, or
invoking an LLM, etc.).
Nodes are linked together by edges which define the flow of the graph (which node the graph will progress to next) and they can be fixed, or conditional (triggering only when some condition is met). This allows for branching structures, as well as loops where nodes iterate on each other until certain requirements are met.
In our case, the first chatbot node houses the LLM agent. It processes the initial query of the user, and the LLM then thinks about what to do next.
When we ask it to find information about Claude on LLM-related subreddits, the LLM will come to the realization that it requires external tools to do this. It will then emit a message which has requests for tool calls, and this will prompt the graph to move on to the tools node, which will attempt to execute the requested tools.
This loop will happen until all the tools that the LLM has deemed necessary have been called, at which point the graph proceeds to the next node which validates the results that have been obtained thus far.
Edge (& Solution)
Edge Case (& solution): As with the unpredictable nature of LLM’s, it can sometimes happen that the model fetches a list of 10 relevant subreddits but then decides that in its initial set of tool calls, it will only search 5 of those in detail, essentially forgetting 5 of the subreddits it was going to search initially.
Because we can store the initial list of subreddits that the tool finds (which we do with the extract_subreddits node and store this list in the graph state), we can also ensure that the model properly invokes all of them, and this is something that we can easily do with the power of LangGraph nodes.
If the validate_results function determines that the model has not called the search_subreddit_for_keyword tool on all the initially fetched subreddits, it will return execution back to the LLM with a list of subreddits still pending.
The model has been instructed via the system prompt, if the pending list contains any subreddits, it must then specifically re-call the necessary tool for those subreddits. With this validation we ensure that even if the LLM happens to make a mistake in determining which tools to call, the validator will guide it back on the right track thus ensuring that it always completes its task successfully.
I quite like LangGraph. Although I found it difficult to pick up at first, I quickly realized the benefits it offers regarding the strictcontrol of execution in the LLM chain. If there’s one thing we know about LLM’s, it’s that they are often too creative and unpredictable – I found LangGraph capable at remedying that.
Robert Komljenović, Software Engineer, Visage Technologies
Once the results have been successfully validated, the graph proceeds to the second to last node, which is the format results node. This node is home to our second LLM, the formatter, which is responsible for outputting the retrieved results (a list of posts from Reddit grouped by origin subreddit) into a nice and readable list for the end-user as a final answer. The LLM has been instructed via a few-shot prompt to produce only valid markdown that can be displayed as such within a Gradio markdown element. Once this LLM call is done, our graph essentially ends and the final string is displayed to the user in the GUI.
LlamaIndex
LlamaIndex is a powerful framework whose agent system is designed to seamlessly handle complex, multi-step tasks by utilizing an LLM- driven internal reasoning loop. Our implementation demonstrates this capability using the ReActAgent (Reasoning and Acting) structure.
The core logic is executed within a simple, two-stage process encapsulated in a single asynchronous function.
LlamaIndex proved to be a practical tool for quickly creating agents without the need to define every individual component. It’s especially useful for prototyping and experimentation, although the framework evolves so rapidly that it can be difficult to keep up with all the new changes and updates.
Sara Pužar, R&D Engineer, Visage Tehcnologies
The first stage, Agent Orchestration and Tool Execution, begins when the user’s query is passed to the ReActAgent.
The agent’s dedicated LLM guided by a specific system prompt and equipped with a list of tools, immediately initiates a dynamic reasoning cycle known as the ReAct loop.
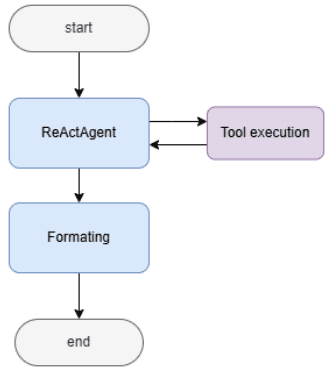
The agent operates autonomously by deciding which tool to call, executing it, and using the tool’s result to determine the next logical action. This cycle repeats dynamically until the agent determines it has gathered all the necessary information. Following the agent’s autonomous data collection, the second stage, formatting, is executed. The raw output generated by the ReActAgent is handed off to a separate, specialized LLM instance.
This secondary model is given a dedicated formatter prompt and is solely responsible for cleaning up the raw content. This isolation ensures the final output in valid markdown.
This agent architecture is powerful because it adopts a declarative model: the developer defines the goals, tools, and constraints, and the LLM itself dynamically determines the necessary micro-steps and tool call sequence to complete the task.
This emphasis on abstraction makes LlamaIndex agents a very fast and flexible option. However, this speed and flexibility come at the cost of the developer losing explicit, step-by-step control over the precise tool execution sequence, which can be a drawback for highly complex systems requiring strict validation logic.
The Core Challenge with LlamaIndex Agent
The core challenge we encountered with the LlamaIndex Agent stems from its highly autonomous, LLM-driven execution model. Given a complex, iterative task, its internal ReAct reasoning loop is prone to premature conclusion. For instance, the LLM might successfully retrieve a list of ten subreddits but then, relying only on its internal chain of thought, decides to skip processing part of them, synthesizing an incomplete answer. This occurs because the agent’s logic acts as a “black box” to developers.
We lack the fine-grained, explicit control of a node-based state machine needed to intercept the agent’s flow after the initial tool call, validate the full list, and force a correction or loop. This absence of a simple, developer-defined safety mechanism leaves the agent’s unpredictable behaviour uncorrected, resulting in a reliability flaw when complex, multi-step validation is required.
Google ADK
Agent Development Kit (ADK) is a framework for developing and deploying AI agents, optimized for Gemini and the Google ecosystem. In ADK, an Agent is a self-contained execution unit designed to act autonomously to achieve specific goals. Agents can perform tasks, interact with users, utilize external tools, and coordinate with other agents.
The agent hierarchy in ADK is defined through the concept of sub-agents – an agent can have multiple sub-agents to which it can delegate tasks according to their description. There must always exist one root agentin the hierarchy – an orchestrator which invokes other sub-agents based on user input.
There are several agent types in ADK. The LLM agent acts as the “thinking” part of the application. It leverages the power of a Large Language Model for reasoning, understanding natural language, making decisions, generating responses, and interacting with tools.
However, due to non-deterministic nature of language models, their behaviour is also non-
deterministic. For example, for solving the problem at hand, one could create a single LLM agent which would have access to three tools: retrieving relevant subreddits, retrieving contents from a subreddit and formatting the output.
However, this solution is highly inconsistent as the LLM will, despite being instructed in the prompt to use all tools, sometimes decide to skip a step. What we want is a mechanism to consistently enforce the use of these tools in a given order.
This is where the other type of ADK agents comes into play – workflow agents which control the execution flow of its sub-agents. There are three types of workflow agents – sequential,
parallel, and loop agents. Since we have three tasks which should be executed in a
sequence, we can use the sequential agent.

The setup is simple. The description of the sequential agent lets the root agent know it is capable of producing formatted Reddit content based on user query. After receiving a query, the root agent will invoke the sequential agent which will invoke its sub-agents in the defined sequence and return the result to the root agent.
As opposed to having one agent with three tools, the sub agents have access to only one tool each, which reduces the chance of encountering an issue with tool calling. Although this setup gives much better results than having only one agent with three tools, it can still be unpredictable at times and requires additional validation.
ADK provides a straightforward way to define multi-agent workflows without the need to manually manage state or handle internal data structures – particularly convenient when working within the Google ecosystem. While ADK shows some inconsistency in tool use and agent coordination, it’s a solid framework overall. More dynamic workflows, however, may require additional validation or custom agents to define behavior at a lower level. This would likely be my tool of choice for Gemini powered projects.
Luka Jančin, Software Engineer, Visage Technologies
The Result
Essentially, we successfully obtained the exact same result (in this case) through all three frameworks (with more or less difficulty) – they all succeed in calling the tools for listing and searching subreddits, as well as handing off the results to the second LLM which formats them into the final markdown.
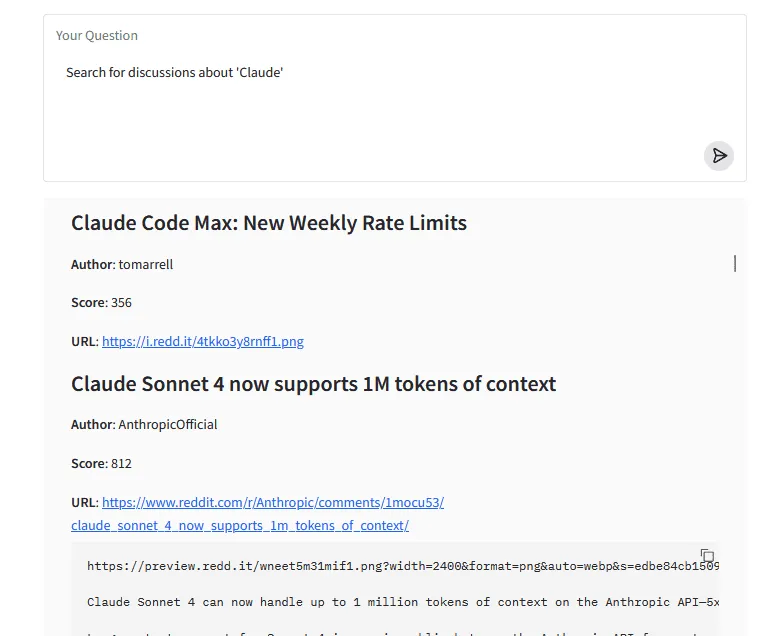
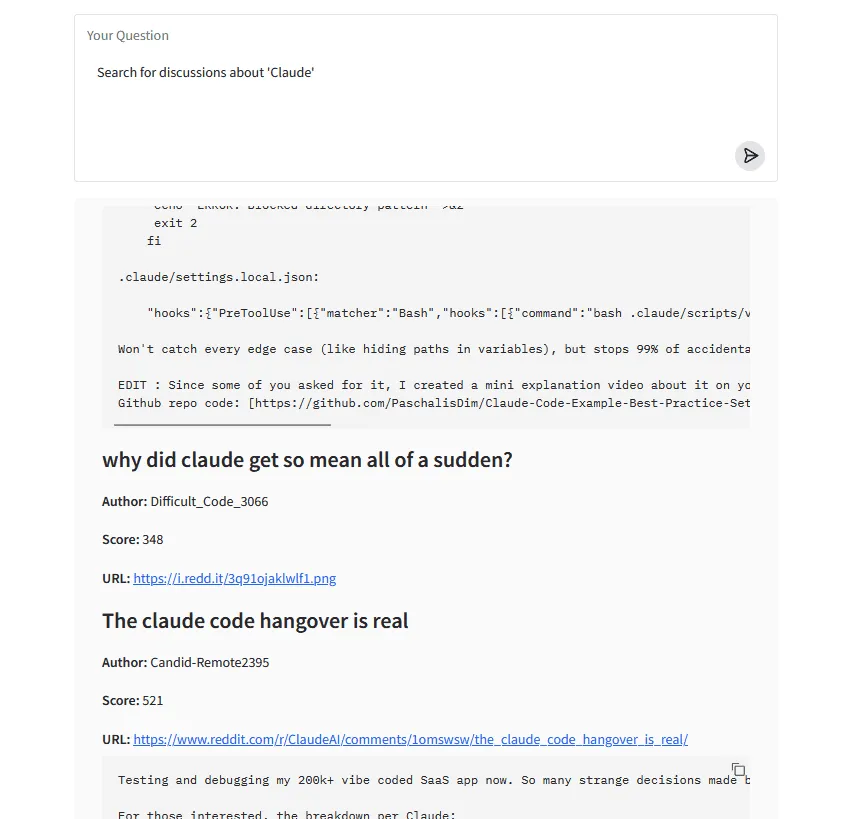
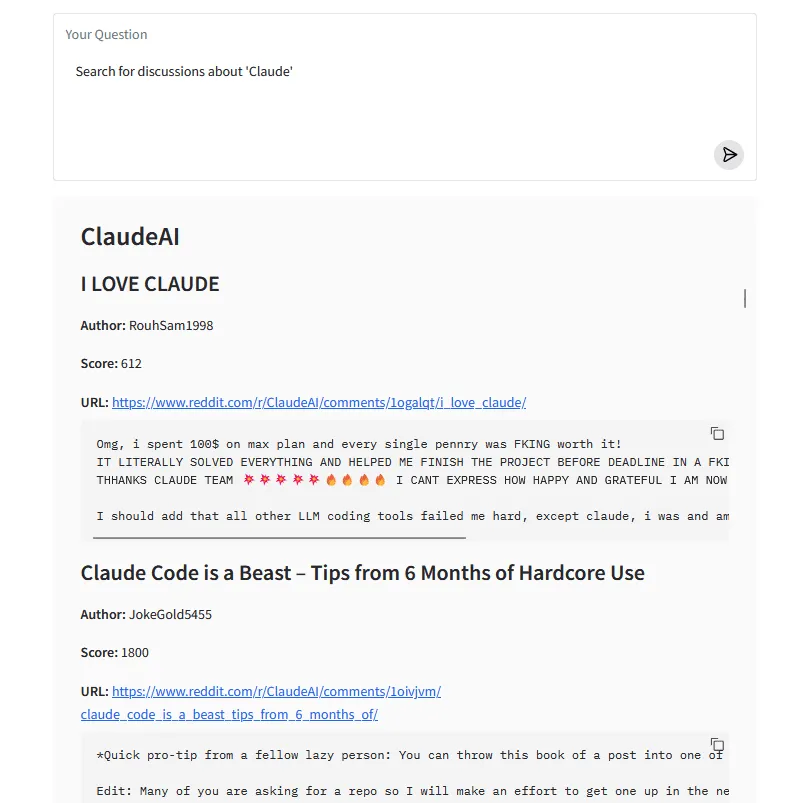
As this is a relatively simple task, the differences do not become so obvious. However, they are more apparent in cases where the LLM fails, which necessitates validation. This is where being able to re-route flow back to the LLM while checking against a list of properly completed tasks comes in very handy, and LangGraph makes this easy.
While this is also possible in other frameworks, it typically requires the use
of another LLM agent as a validator.
Framework pros & cons table
| LangGraph/LangChain | LllamaIndex | Google ADK |
|---|---|---|
| Offers high granularity and level of control over every step of the chain ✅ | Generally easier to start due to high-level abstraction ✅ | Intuitive agent types ✅ |
| Can be complex; even a basic graph requires good understanding of how to properly define nodes & edges ❌ | The agent’s LLM-driven internal loop makes it fast but less transparent than explicit graphs, leading to a “black box” effect ❌ | Issues with continuity and execution order of instructions given to agents ❌ |
| Documentation is somewhat confusing and broken in some places ❌ | Extensive but complex; suffers from frequent API changes ❌ | Decent documentation ✅ |
| Good integration with a wide variety of model providers ✅ | Highly model-agnostic ✅ | Should integrate the best with Gemini models (in theory) ✅ |
| Intuitive debugging & graph visualization GUI ✅ | Observability built around tracing steps and agent thought processes (less focus on visual flow) ✅ | Ongoing bugs regarding tool-calling and structured output ❌ |
Conclusion
Now that we have implemented the necessary features in all three frameworks, we can look at the outcomes and specifics of each implementation. In practice, when working on a project with a set framework in mind one would adapt to the capabilities of the framework and work with its strengths while trying to minimize its shortcomings.
This might mean that you would have to strengthen the model prompt in areas where the framework itself doesn’t provide you the tools to reign in the behavior of the model. For the sake of this comparison, we tried to keep variables such as prompts and model count the same between the frameworks, which sets up a level playing field to compare the frameworks themselves.
LlamaIndex and Google ADK both provided us with an easy to understand, high-level abstracted API that made it relatively simple to set up the required agents and the flow between them. ADK web visualizes flow pretty well and is a useful tool for debugging, while the simple sequential agent types make it easy to define the overall flow of the LLM chain.
Where these two frameworks faced their limitations was in the area of validation. Neither Llama nor ADK offer a simple way to redirect the flow of the LLM execution back to the original agent, at least not without using a third LLM acting exclusively as a validator.
LangGraph has the upper hand in this scenario. With its ability to tightly control node execution and return the flow to the original agent if there are incomplete tasks, we can have the single agent essentially ‘self-validate’, thus saving on tokens and reducing the overall complexity and number of agents. This, of course, required a somewhat more complex setup of nodes and (conditional) edges, which requires you to think about and plan your graph’s flow well in advance, as the setup in code gets complex quickly.
Thankfully, the built-in Langgraph Studio offers good debugging capabilities as well as excellent visualization of the graph’s flow. The conclusion, as always, is that all frameworks have their pros and cons, and one must choose the right tool for the job. If working exclusively with Gemini models, ADK might be the way to go due to tight integration with Google’s own models, as well as being fairly intuitive
and easy to set up.
If a generally user friendly and capable framework is required, LlamaIndex is probably the fastest to set-up and understand while still being quite powerful if one wants to dive deeper into the API. Still, if maximum control over every step of the process is a must, there is no defeating LangGraph and its ability to define each and every step of the graph and implement all kinds of conditional flows and loops. They all have their time and place and it’s simply a matter of what is the most appropriate for your project, or what you are the most comfortable working with.