Why Data Pipelines Are as Critical as Algorithms in Autonomous Robotics

A flawed data pipeline can lead to mistakes, crashes, or failures.
Real-world incidents highlight that system reliability depends on detection algorithms, but also on how data is processed and interpreted throughout the pipeline. In the 2018 Uber automated vehicle crash, the vehicle’s sensors detected a pedestrian, but failures in the perception pipeline led to incorrect classification and delayed response, ultimately preventing timely braking.
- What Is a Data Pipeline?
- Sensor Landscape in Autonomous Robotics
- Why Raw Sensor Data Isn’t Enough: Pipeline Information Processing and Organization
- Sensor Fusion: Combining Multiple Inputs
- Real-Time Processing for Safe Operation
- Scaling Autonomous Robotics: Data Infrastructure
- Autonomous Robotics Systems in High-Stakes Environments
- Expanding Applications: Agriculture and Marine Environments
- Why Strong Data Pipelines Matter
Recent progress in robotics has greatly improved how robots see and make decisions on their own, enabling them to move through complex spaces, detect obstacles, and adapt to changing conditions. Still, their reliability is not just about the algorithms they use. Every self-operating machine depends on a data pipeline that gathers, processes, and delivers sensor information in real time.
In places like warehouses, hospitals or construction sites, this dependence becomes even more evident. Data pipelines are as critical as the algorithms themselves, ensuring that sensor information is consistently processed, aligned, and delivered in real time. A well-designed pipeline supports accurate perception and timely reaction, while stable, high-quality data streams ultimately determine how effectively a machine can interpret its surroundings and respond.
What Is a Data Pipeline?
A data pipeline is a system designed to collect raw data from different sensors, transform it into structured information, and move it to a designated destination. By automating the movement of data, data pipelines ensure that information flows reliably and securely from where it is created to where it’s needed. With this information, an automated machine can:
- perceive the world
- make decisions
- operate, and
- learn from experience.
Sensor Landscape in Autonomous Robotics
Understanding the importance of data pipelines begins with how these systems perceive the world. They use multiple sensors, each providing distinct information.
Cameras
Each camera type is suited to specific tasks. Standard RGB cameras are widely used for object detection, classification, and scene understanding thanks to their rich visual detail. Stereo cameras add depth perception by comparing two viewpoints, making them useful for estimating distances in real time. Event-based cameras, which capture changes in brightness rather than full frames, are particularly effective for detecting fast motion with low latency. Thermal and infrared cameras extend perception into low-light or nighttime conditions by detecting heat signatures instead of visible light.

The camera’s frame rate controls how often new visual information arrives; if it’s too slow, fast-moving objects may be missed, leading to delayed reactions.
Because cameras generate high-resolution streams, these must be efficiently processed, aligned with other sensors, and synchronized in real time. For example, a camera image has to be matched with a LiDAR scan so both show the same moment.
LiDAR
LiDAR (Light Detection and Ranging) emits laser pulses and measures the time it takes for them to return after reflecting off surfaces. This produces point clouds representing the spatial layout of the environment. LiDAR is highly accurate for measuring distances and detecting obstacles, even in low-light conditions.
However, LiDAR data are dense and computationally heavy. The system must process thousands to millions of points per second, align them with other sensor inputs, and remove noise from reflections, rain, dust, or reflective surfaces. Misaligned or unsynchronized LiDAR data can distort a robot’s perception of distance or object location, leading to navigation errors. In the mentioned 2018 Uber automated test vehicle crash, for example, the system registered the pedestrian through radar and LiDAR several seconds before impact, yet the perception pipeline repeatedly misclassified the object and failed to react in time.
LiDAR types
LiDAR systems can be broadly classified into two types: coherent and incoherent, based on how they generate and detect laser signals.
- Coherent LiDAR, on the other hand, uses single-frequency lasers and detects phase or frequency shifts, enabling more sensitive measurements and direct velocity estimation through Doppler effects. Those are often used in advanced applications such as velocity sensing, long-range detection, and some experimental autonomous driving platforms.
Wavelength choice is also important. Many systems operate around 905 nm due to cost and practicality, while 1550 nm allows higher power with eye safety but comes with higher cost and limitations such as water absorption and less mature detectors.
Radar
Radar sends out radio waves and measures how they bounce back from objects. Unlike cameras, radar can spot things even in fog, smoke, or rain. Its data isn’t as detailed as LiDAR, but it’s very good at detecting movement and speed.
Because radar measurements have different characteristics and time delays than cameras or LiDAR, integrating radar into the data pipeline requires careful time alignment and calibration. Sensor fusion ensures that radar information complements other sensor types instead of introducing inconsistencies.
GNSS
GNSS (Global Navigation Satellite Systems) is the industry term for systems like GPS, GLONASS, Galileo, and BeiDou. It enables global positioning and is essential for outdoor navigation, route planning, and large-scale operations.
GNSS is widely used in autonomous lawn mowers, agricultural machinery, and off-highway vehicles. For example, robotic mowers often combine GNSS with RTK (Real-Time Kinematic) corrections to maintain precise boundaries and navigate large areas without physical guides.
These systems face several challenges. Signal degradation can occur near buildings, under dense vegetation, or on uneven terrain. Multipath effects, where signals reflect off surfaces, can cause positioning errors. Temporary signal loss is also common, so systems often use sensor fusion with MUs, LiDAR, or visual odometry to maintain accurate localization.
As a result, GNSS is rarely used alone. It is typically part of a broader positioning pipeline that ensures continuity and accuracy in imperfect conditions.
IMUs (Inertial Measurement Units)
IMUs measure things like orientation, acceleration, and rotation, helping track a robot’s movement in 3D space. Over time, IMUs can drift, which means small errors add up. The pipeline needs to combine IMU data with other sensors like GPS or LiDAR to fix this drift and keep the positioning accurate.
In safety-critical robotics applications like industrial automation, autonomous vehicles, and off-highway machines, the integrity of these sensor data streams is particularly important.
Industry safety frameworks like Functional Safety (FuSa) and Safety of the Intended Functionality (SOTIF) highlight the need for strong perception systems and careful validation of AI-driven features. These standards are guiding how robotics developers build data pipelines and perception systems for real-world use, as discussed in Functional and AI Safety for Off-Highway and Industrial Vehicles – FuSa & SOTIF.
Why Raw Sensor Data Isn’t Enough: Pipeline Information Processing and Organization
Raw sensor data is rarely sufficient for safe autonomous operation. Each sensor produces streams that are noisy, incomplete, or unstructured.
Cameras capture images but cannot directly measure distances. LiDAR generates point clouds but cannot distinguish objects without contextual interpretation. IMUs track movement but accumulate drift errors. To make these raw sensor streams actionable, a data pipeline processes and organizes the information so the perception system can operate reliably. This process has several key steps:
1. Synchronization
Each sensor runs at a different frequency and may have different delays. Synchronization aligns data streams in time so that all measurements correspond to the same instant. Without synchronization, the autonomous device may combine mismatched sensor readings, causing misperceptions of object location or movement.
2. Filtering and Cleaning
Raw data often has noise, like visual glitches, reflections, or sensor errors. Filtering gets rid of outliers and fixes distortions. For example, if LiDAR bounces off a glass wall and creates false points, the pipeline needs to remove them before the robot uses the data.
3. Standardization
Sensors create data in many formats, like images, point clouds, radar signals, or numbers. Standardization changes these into a common format so the autonomous system can process them together.
4. Buffering and Preprocessing
Preprocessing prepares the input for real-time use. It may involve normalizing values, compressing large streams, or generating summaries that reduce processing load without losing critical information. Buffering ensures smooth data delivery, even if a sensor temporarily produces data faster or slower than expected.

Without these steps, multimodal sensor streams can quickly become inconsistent or unusable, leading to navigation errors, delayed reactions, or unsafe behavior.
Sensor Fusion: Combining Multiple Inputs
After preprocessing, data from multiple sensors is combined to create a consistent understanding of the environment. However, since no single sensor can provide a complete picture, combining data from multiple sensors is necessary for accurate perception. Sensor fusion integrates multiple streams to generate a coherent, accurate representation and enhance robustness against sensor noise or failure. Sensor fusion can be categorized into three main approaches based on when sensor data is combined.
Low-level fusion (LLF)
Low-level fusion, also known as data-level fusion, combines raw sensor measurements before significant processing. The system integrates unprocessed data streams from cameras, LiDAR, radar, or IMUs to create a unified representation of the environment.
Example for object detection:
- LiDAR provides 3D point clouds, and cameras provide 2D images. LLF projects LiDAR points onto the image plane and integrates the raw information to create a dense 3D map with both color and distance information.
- Radar measurements of velocity are combined directly with raw LiDAR or camera signals to enhance detection of moving objects.
The LLF approach offers the most comprehensive data for detection and perception and enables accurate alignment of sensor measurements. Still, it requires high computational resources because raw input is large and dense. Sensors must be tightly synchronized, otherwise it can produce inaccurate results.
Mid-level fusion (MLF)
Mid-level fusion, or feature-level fusion, combines data after preliminary processing or feature extraction. Sensors convert raw measurements into intermediate features such as edges, clusters, object proposals, or motion vectors, which are then integrated during fusion.
Example for object detection:
- A camera extracts bounding boxes for potential objects, and LiDAR generates clusters of 3D points. MLF combines these feature sets to confirm object existence, position, and orientation.
- Radar provides velocity estimates of detected clusters, which are merged with camera and LiDAR features for tracking.
The biggest advantages of MLF are reduced computational load compared to LLF, as raw data is preprocessed into features. This approach preserves most of the useful information for object detection and tracking. But its accuracy depends on the quality of feature extraction.
High-level fusion (HLF)
High-level fusion, or decision-level fusion, combines the outputs of individual sensor-based detection systems. Each sensor independently detects objects and generates hypotheses (e.g., “Obstacle detected at (x,y,z)”). The fusion system integrates these decisions to produce a final, consistent perception output.
Example for object detection
- A camera detects a pedestrian and assigns a confidence score.
- LiDAR detects a cluster corresponding to the same pedestrian, and radar detects velocity. HLF combines these outputs to confirm the pedestrian’s position and motion.
This approach requires minimal computational resources, as only final decisions are fused. It also remains robust to sensor failures, since other sensors can still contribute if one fails. However, it offers less precision than LLF or MLF, as detailed measurements are discarded.
Real-Time Processing for Safe Operation
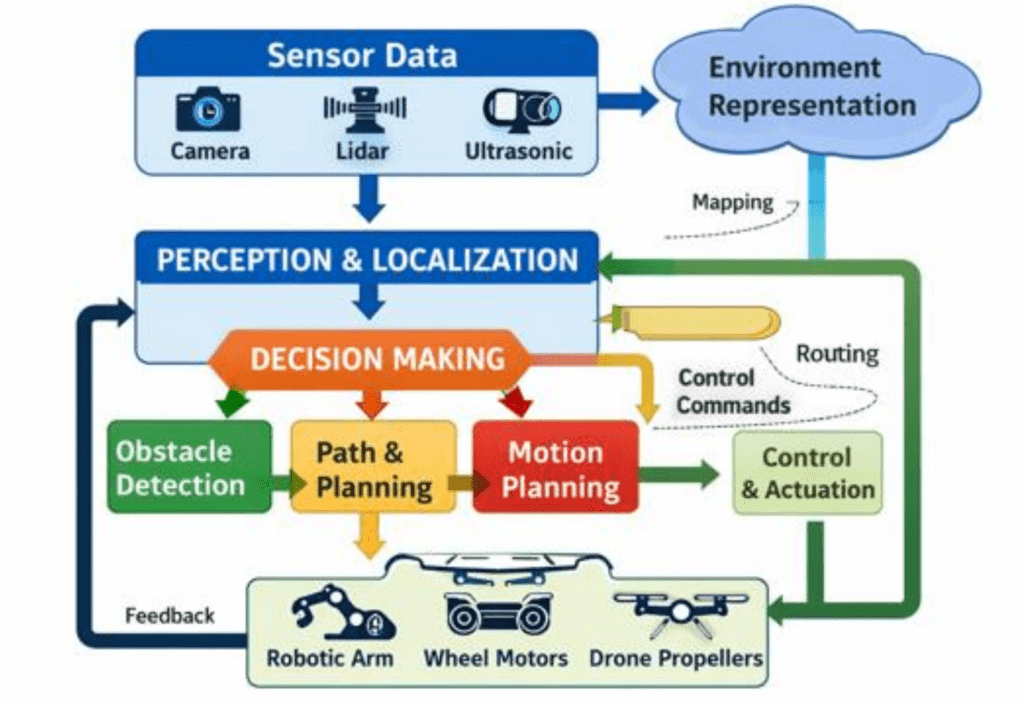
Once sensor fusion consolidates information from each source, the autonomous robotic system has to process it and respond rapidly for safe operation. Key parts of this processing include:
- Sensing, which involves using devices such as cameras, lidar, or GPS to gather raw data from the environment
- Perception stage, during which the system processes and interprets this data to identify objects, obstacles, and its own position
- Decision-making with obstacle detection and planning stage, where algorithms analyze the interpreted information and select the most appropriate action based on goals, rules, or learned behavior, and determine how to execute the movement or task
- Performing the action using the autonomous robotic system’s motors or actuators. The results are then fed back into the system, enabling continuous adjustment and adaptation to environmental changes
Scaling Autonomous Robotics: Data Infrastructure
One robot with multiple cameras, LiDAR units, radar sensors, and IMUs can generate terabytes of data in minutes. Fleets of such systems produce petabytes, requiring sophisticated infrastructure for collection, storage, and processing.
Managing large volumes of information requires advanced infrastructure that supports data ingestion, reliable storage, and efficient processing. Distributed storage and cloud-based architectures are often used to provide scalability, fault tolerance, and fast data access.
Edge computing has also become a critical component in managing data flow. By conducting initial processing in proximity to sensors, edge systems enhance real-time processing and lower latency. The localized processing allows systems to respond more quickly and improves overall reliability, while also reducing dependence on centralized cloud infrastructure. In safety-critical contexts, minimizing processing delays is necessary, as they can directly influence system performance.
Autonomous Robotics Systems in High-Stakes Environments
Autonomous robots increasingly operate in real-world, high-stakes environments where mistakes can have serious consequences.
- Logistics and Manufacturing: AMRs transport goods, manage inventory, and assist human workers in busy spaces. Pipelines must handle moving obstacles, dense layouts, changing lighting, and human-machine interactions to maintain safe and efficient operations.
- Outdoor and Hazardous Settings: Self-driving vehicles, mining robots, and exploration robots face unpredictable weather, rough terrain, and moving obstacles. Reliable data flows enable them to adapt to sudden changes and maintain accurate situational awareness, preventing accidents in critical scenarios.
Expanding Applications: Agriculture and Marine Environments
Robotics deployments are expanding beyond structured industrial settings into environments with weaker infrastructure, greater uncertainty, and stricter operational constraints.
Autonomous robotics in agriculture faces challenges distinct from those in warehouses or buildings like hospitals. Perception systems must manage unstructured terrain, variable crop geometry, occlusions, and changing illumination. These systems often rely on multi-modal sensing (RGB, multispectral, LiDAR) combined with GNSS and, in many cases, RTK corrections for improved positioning accuracy.
Pipelines must address intermittent connectivity, sensor degradation from dust or vibration, and localization drift over large areas. Efficient on-device preprocessing and selective logging are commonly used to minimize bandwidth while supporting offline model training and diagnostics.
Autonomous marine systems operate under even stricter constraints, especially during subsea and long-duration missions without GPS. Navigation depends on multi-sensor data fusion, combining inertial navigation systems (INS), Doppler velocity logs (DVL), sonar, and acoustic positioning.
These systems must address inertial drift and varying sensor uncertainties. Limited communication bandwidth and high latency require onboard processing and decision-making. Multi-sensor integration also presents challenges in synchronization and robustness, so systems must tolerate partial sensor failures, reduced visibility, and intermittent localization updates.
In both domains, data pipeline design is critical to system robustness. Unlike controlled environments, these systems cannot depend on ideal conditions, so pipeline resilience must be a primary design constraint.
Why Strong Data Pipelines Matter
Self-operating machines depend on accurate, timely, and reliable sensor data. The pipeline determines whether that information is synchronized, clean, and available when needed.
A robust data flow:
- Synchronizes and fuses multimodal sensor data
- Filters noise and handles errors
- Delivers information in real time
- Scales to handle increasing sensor volumes and multiple machines
Without these pipelines, autonomous systems may function well in controlled settings but fail in the dynamic environments where they are deployed. A strong data pipeline is not just a technical component – it is the foundation of safe and reliable autonomous robotics.