Optimizing inference engines: One API to rule them all

Inference engines play a critical role in many AI applications. The thing is, as deep learning keeps on advancing, we need more powerful inference engines that can handle the load and provide us with fast and accurate results.
So, how did we tackle this here at Visage Technologies?
Well, we eagerly started working on improving our own inference engine, but then we realized that it would be smarter to use existing optimized open-source options. Stick with us as we take you behind the scenes, spilling the beans on the challenges and solutions we found along the way.
What is an inference engine?
In general, an inference engine is a component of an AI system that applies logical reasoning and draws conclusions based on available information or rules.
The engine takes input data and runs it through a bunch of algorithms and rules. It crunches numbers, does computations, and comes up with results or recommendations based on its analysis.
In other words, an inference engine is like the brain behind the scenes that helps make sense of all the data. So, naturally, it’s a big deal in different fields like natural language processing, machine learning, and knowledge-based systems.
In our use case, an inference engine is a powerhouse that runs our neural network models in the most efficient way possible.
① Challenge: an outdated inference engine
Our initial in-house inference engine was based on OpenBLAS. It used a Vinograd algorithm, was fast with low memory consumption, and supported multiple file formats.
However, as the deep learning community progressed, we found that our engine lacked layers and was limited to sequential convolutional neural networks (CNNs). It simply could not keep up with the rapidly changing and diverse architectures in the field.
We wanted a faster engine with multiple platform support and more layers. So, we got into our lab and started experimenting with other engines.
② Experimentation: the search for better inference
In our search for better alternatives, we experimented with several inference engines.
However, we faced difficulties with different data layouts, documentation issues, framework conversion problems, and speed. Additionally, we wanted to keep our models private and secure.
– Desktop platforms
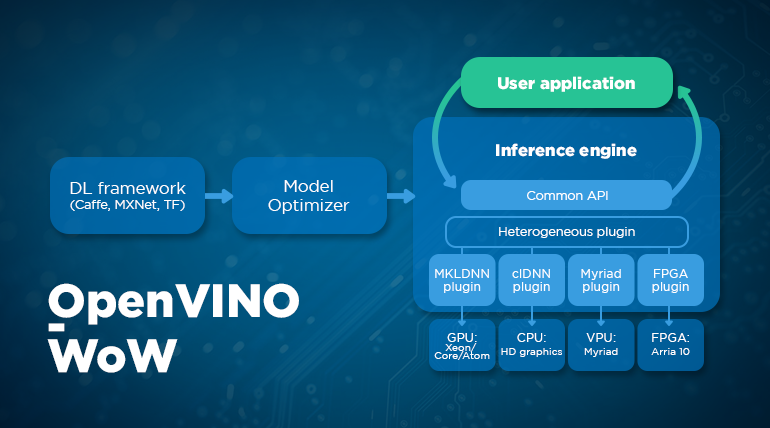
Ultimately, for desktop platforms, we chose OpenVINO – a highly optimized inference engine available on Intel’s 64-bit platforms – Windows, Linux, and macOS.
OpenVINO is a powerful tool that allows for high optimization and heterogeneous execution. This means that it can support a wide range of different hardware and can be used to run models across multiple devices, including CPUs, GPUs, and other accelerators.
To use OpenVINO, you must first convert your trained model into OpenVINO’s format. This is done using the model optimizer, which transforms your model into an intermediate representation that can be used with OpenVINO’s inference engine.
So, what exactly are model optimizations?
Model optimizations are a set of techniques used to improve the performance of machine learning models. For example, if your network has multiple layers (such as a convolutional layer on top, followed by multiplication, addition, etc.), they can be fused into one layer, resulting in a 20% performance boost.
Once it’s optimized, you can easily run your model with an inference engine. Since it now supports heterogeneous execution, you can run it on CPU, GPU, Movidius platform, and more.
This covers desktop, but what about mobile and embedded platforms?
– Mobile and embedded platforms
When it comes to mobile and embedded platforms, this is where we turned to TensorFlow Lite.
TensorFlow Lite supports quantization, which allows for improved performance on mobile and embedded platforms. It also supports various delegates that aid in optimization, such as the GPU delegate.
Finally, not only is it compatible with Raspberry Pi, Android, and iOS, but it also supports Windows and Linux. This versatility can be incredibly useful as it lets you utilize desktop environments for debugging purposes, even while working on mobile platforms. It’s the best of both worlds.
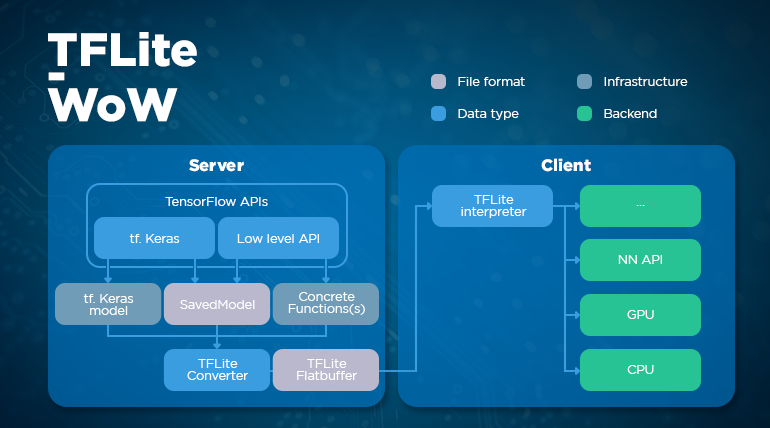
To use TensorFlow Lite, you must first convert your trained model into its format using the built-in converter. TensorFlow Lite is especially fast on Android platforms, providing two to fourteen times faster inference speed compared to our own inference engines.
Overall, both OpenVINO and TensorFlow Lite are powerful tools that can help optimize and run machine learning models. Which tool you choose will depend on your specific needs and hardware constraints.
③ Inference optimization: one API to rule them all
Before we can run our models, we need to make sure they’re in the right format. This is especially important when we’re working with different machine learning frameworks like PyTorch, TensorFlow, and OpenVINO, which all have their own specific requirements.
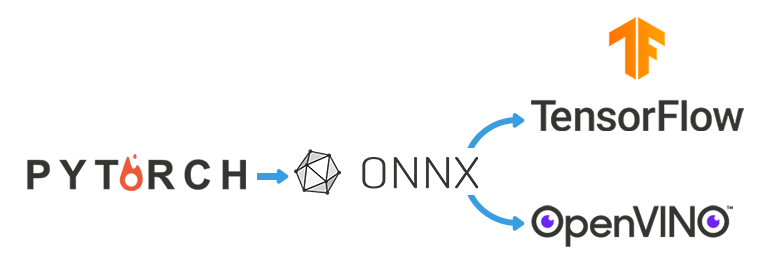
For example, PyTorch uses its own format for model representations, while TensorFlow and OpenVINO require different formats. This is where ONNX (Open Neural Network Exchange) comes in. ONNX serves as a bridge between PyTorch and other frameworks. It is considered a standard for representing any neural network.
First, we convert our PyTorch models to the ONNX format and then from ONNX to Keras (TensorFLow format). Once we’re in the TensorFlow ecosystem, we can use a built-in converter to get the final TensorFlow Lite model. However, ONNX isn’t officially supported by TensorFlow, so we use a third-party program (such as this open-source one) to help with the conversion.
OpenVINO supports conversion from ONNX to OpenVINO format.
Creating our own inference wrapper – ViNNIE
To ensure the best run-time and performance across different platforms, we decided to support multiple inference engines by creating our own inference wrapper – ViNNIE (Visage Neural Network Inference Engine).
ViNNIE works as a plugin system where each inference engine is encapsulated into a separate plugin. This way ViNNIE unifies different inference engines with a simple API. It has an initialization method and a forward method. This makes it easy to add support for new inference engines on separate platforms.
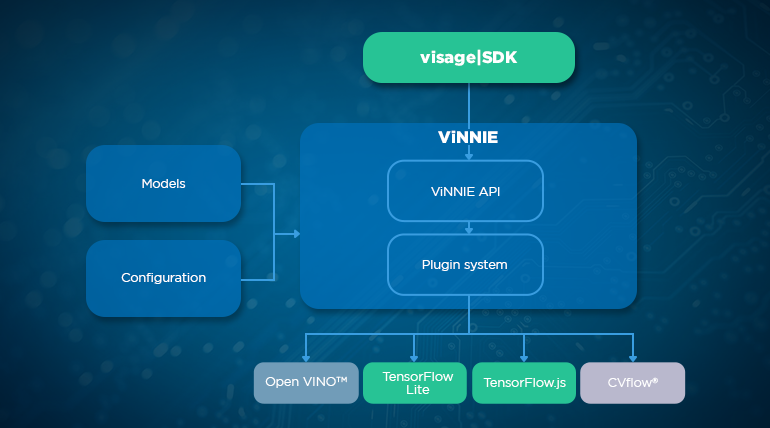
To add support for a new inference engine, all that’s needed is to implement it within the plugin and register it in the main core library. One way to do this is by storing all the plugins in the same directory and loading them from there.
ViNNIE can be configured through a configuration file or through an API. You can set the number of threads that the inference engine will use and the preferred inference engine. However, in some cases, such as using OpenVINO on the Android platform, it may not work as expected. To handle these situations, we’ve implemented a fallback mechanism that automatically selects the most suitable inference engine for the task at hand.
Moreover, it’s very simple to use our inference engine and add new functionalities on top of it (for example, model protection). The plugin mechanism enables the easy introduction of new inference engines.
This makes introducing new inference engines and, therefore, optimizing performance a piece of cake.
What does the benchmark say?
We benchmarked OpenVINO, TensorFlow Lite, and our own in-house inference engine using a Google Mesh Park library. We used a model that had about 1 million parameters in nine layers, and only one thread.
The result? OpenVINO provided about five times faster inference compared to our in-house engine.
| Inference engine | Time [ms] |
|---|---|
| Visage in-house inference engine | 15 |
| OpenVINO | 2.9 |
| TensorFlow Lite | 3.4 |
| ViNNIE benchmark (Windows). Measurements are done with Google Benchmark Library. |
The performance difference on Android was even wider. When we tested that same model on Android, even the worst version of TensorFlow Lite had up to seven times higher performance than our inference engine.
| Inference engine | Time [ms] |
|---|---|
| Visage in-house inference engine | 73 |
| TensorFlow Lite (CPU-float) | 11 |
| TensorFlow Lite (GPU-fp32) | 10 |
| TensorFlow Lite (GPU-fp16) | 6 |
| ViNNIE benchmark (Android) |
As a cherry on top, TensorFlow Lite provides optimizations for the GPU, which can make it even faster.
We found that the GPU performance was almost two times faster than the CPU performance. In some cases, the performance gap was even wider because TensorFlow has better cache handling on the CPU side.
Setting the stage for incredible AI applications
Our journey in optimizing our in-house influence engine led us to experiment with various inference engines and ultimately choose OpenVINO and TensorFlow Lite.
Implementing these engines and respective optimization techniques was a game-changer. We achieved faster and more efficient inference, which was super exciting.
Our own inference wrapper – ViNNIE – played a crucial role in maximizing the performance. This nifty tool allows us to introduce new inference engines easily. So, if we come across another amazing engine in the future, we can simply plug it into Vinnie and enjoy the benefits.
And there you have it – the story of how we successfully optimized our in-house inference engine has come to an end. But it’s also a delightful new beginning for even more incredible AI applications. We can’t wait to explore future applications and performance boosts that are yet to come. ☺
Try out visage|SDK
Get started with cutting-edge face tracking, analysis, and recognition technology today.


